What is a disaster
recovery in SQL Server?
A SQL Server disaster is an event that causes data loss or any serious SQL Server disruption. Causes of a disaster can be numerous: power failure, hardware failure, virus attack, natural disaster, human error, etc. Some SQL Server disasters cannot be prevented. That’s why a good disaster recovery plan is important
A SQL Server disaster recovery plan (DRP) is a process to have SQL Server up and running, and to overcome data loss after a disaster. A disaster recovery plan must be planned and documented in order to prevent catastrophic data loss and incidents
High-Availability is the term that shows the percentage of time a system needs to be available. In some environments, it goes as high as 99.999% or just 5.26 minutes downtime per year.
A SQL Server disaster is an event that causes data loss or any serious SQL Server disruption. Causes of a disaster can be numerous: power failure, hardware failure, virus attack, natural disaster, human error, etc. Some SQL Server disasters cannot be prevented. That’s why a good disaster recovery plan is important
A SQL Server disaster recovery plan (DRP) is a process to have SQL Server up and running, and to overcome data loss after a disaster. A disaster recovery plan must be planned and documented in order to prevent catastrophic data loss and incidents
High-Availability is the term that shows the percentage of time a system needs to be available. In some environments, it goes as high as 99.999% or just 5.26 minutes downtime per year.

• Failover clustering
• Database mirroring
• Replication
• Log shipping
• Backup and restore
Each solution has its own advantages and cost of implementing. Based on the needs, a disaster recovery plan should include on one or more available solutions.
SQL Server failover clusters:
SQL Server failover clusters are made of
group of servers that run cluster enabled applications in a special way to
minimize downtime. A failover is a process that happens if one node crashes, or
becomes unavailable and the other one takes over and restarts the application
automatically without human intervention.

The Backup and restore technique:
The Backup and restore technique should
be used as basic option for assurance. There are two major concepts involved:
backing up SQL Server data and restoring SQL Server data. Backed up data is
moved to a neutral off-site location and restore is tested to assure data
integrity. There are different types of backups available in SQL Server: a full
backup, differential backup, transaction log backup, and partial backup. The
backup strategy defines the backup type and frequency, how backups will be
tested, and where and how backup media will be stored. The restore strategy
defines who is responsible for performing restores and how restores should be
performed to meet availability and data loss goals.

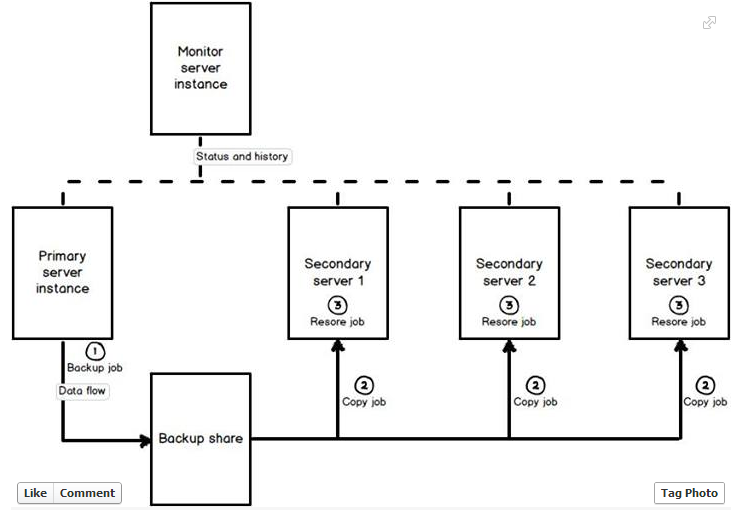
Log shipping:
Log shipping is based on automated
sending of transaction log backups from a primary SQL Server instance to one or
more secondary SQL Server instances. The primary SQL Server instance is a
production server, while the secondary SQL Server instance is a warm standby
copy. There can be a third SQL Server instance which acts as a monitoring
server. The log shipping process consists of three main operations: creating a
transaction log backup on the primary SQL Server, copying the transaction log
backup to one or more secondary servers, and restoring the transaction log
backup on the secondary server.
Replication:
Replication can be
used as a technology for coping and distributing data from one SQL Server
database to another. Consistency is achieved by synchronizing. Replication of a
SQL Server database can result in benefits like: load balancing, redundancy, and offline processing. Load balancing allows
spreading data to a number of SQL Servers and distributing the query load among
those SQL Servers. A replication consists of two components:
• Publishers - databases that provide data. Any replication may have one or more publishers
• Subscribers - databases that receive data from publishers via replication. Data in subscribers is updated whenever data the publisher is modified
Microsoft SQL Server supports three types of database replication:
• Merge replication: allows the publisher and subscriber to independently make changes to the database. The merge replication agent checks for changes on both sets of data and modifies each database accordingly. If changes conflict with each other, it uses a predefined conflict resolution algorithm to determine the appropriate data
• Publishers - databases that provide data. Any replication may have one or more publishers
• Subscribers - databases that receive data from publishers via replication. Data in subscribers is updated whenever data the publisher is modified
Microsoft SQL Server supports three types of database replication:
• Merge replication: allows the publisher and subscriber to independently make changes to the database. The merge replication agent checks for changes on both sets of data and modifies each database accordingly. If changes conflict with each other, it uses a predefined conflict resolution algorithm to determine the appropriate data
• Snapshot replication: the publisher makes a snapshot of the entire database and makes it available for all subscribers
• Transactional replication: uses replication agents which monitor changes on the publisher and transmit these changes to the subscribers

Database mirroring:
Database mirroring is
a solution for increasing availability of a SQL Server database. It maintains
two exact copies of a single database. These copies must be on different SQL
Server instances. Two databases form a relationship known as adatabase mirroring session. One instance acts as the
principal server, while the other is in the standby mode and acts as the mirror
server. Two SQL Server instances that act in mirroring environment are known as
partners, the principal server is sending the active portion of a transaction
log to the mirror server where all transactions are redone
There can be two types of mirror servers: hot and warm. A hot mirror server has synchronized sessions with quick failover time without data loss. A warm mirror server doesn’t have synchronized sessions and there is a possibility of data loss
This solution will be removed in future versions of SQL Server .
There can be two types of mirror servers: hot and warm. A hot mirror server has synchronized sessions with quick failover time without data loss. A warm mirror server doesn’t have synchronized sessions and there is a possibility of data loss
This solution will be removed in future versions of SQL Server .

No comments:
Post a Comment